
Apr 30, 2025 · 6 min read
TranscriptFormer: A Generative Cross-Species Cell Atlas Across 1.5 Billion Years of Evolution
We are building toward a virtual cell model to predict and understand cell behavior.
A fundamental challenge in biomedical research is a limited understanding of the unique role, function, and behavior of each individual cell within the human body. CZI is working to solve key biological questions — anchored in four grand scientific challenges — that will demystify the inner workings of human biology to accelerate breakthroughs to significantly decrease the burden of human disease.
One of these challenges is to build an AI-based virtual cell model over the next few years to predict and understand cellular behavior — simulating biology across scales, time frames and scientific modalities (see Bunne et al, Cell 2024).
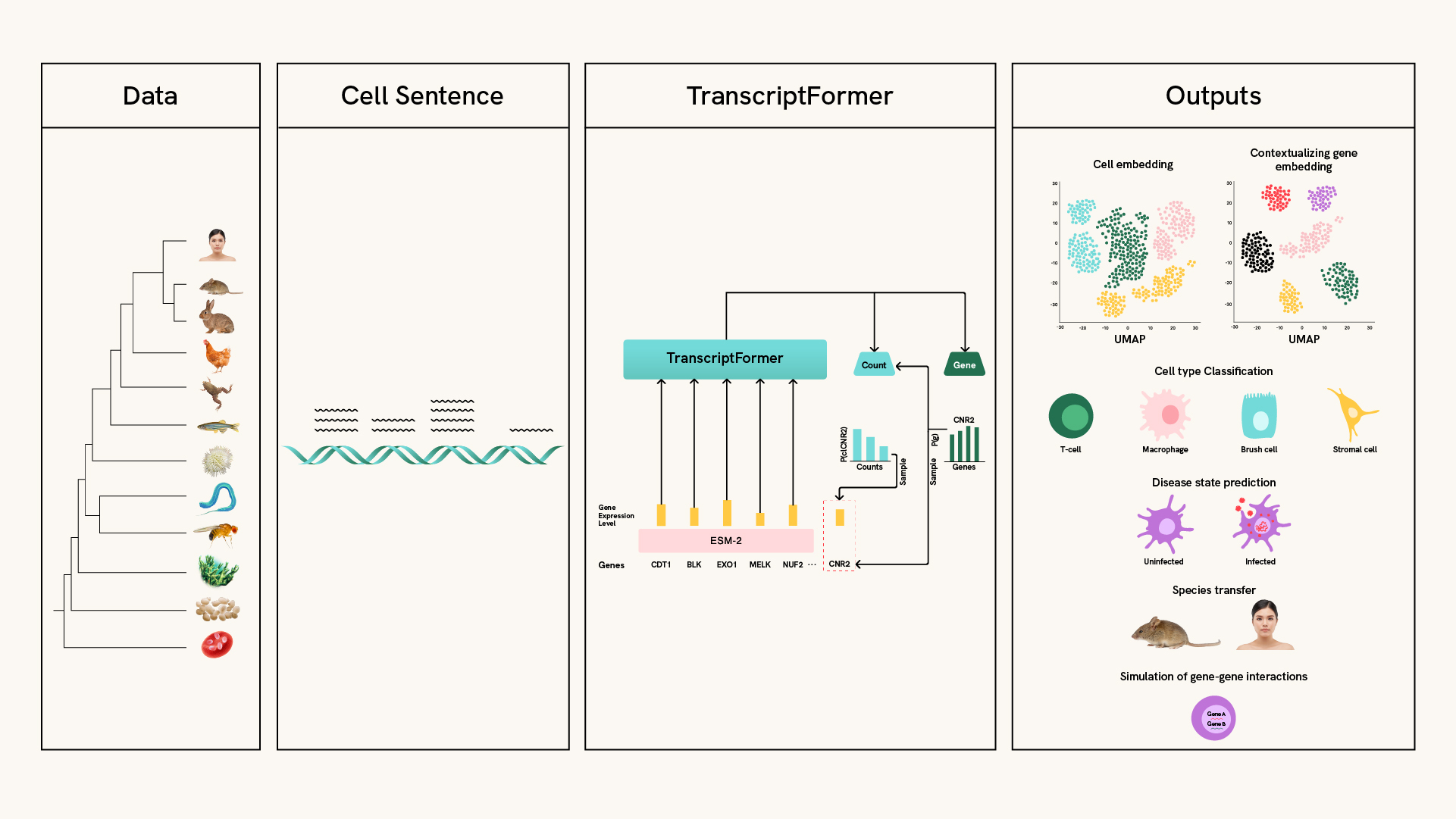
On the path to building a virtual cell, CZI has invested in cell atlases like those compiled in CZ CELLxGENE, and prioritized its data generation roadmap with its Billion Cells Project, identifying large-scale single-cell measurements as a key source of cellular readouts. As an important step in utilizing these resources, we are proud to release the TranscriptFormer single-cell model, which marks our next step to turn such cell atlases into interactive models. TranscriptFormer is built on top of cell atlases of diverse species across evolution and development. It can be used as a virtual instrument, allowing researchers to work with single-cell data by asking questions as prompts and testing in-silico hypotheses before running experiments in a lab.
A Generative Model That Can Generalize Biology Across Vast Evolutionary Distances
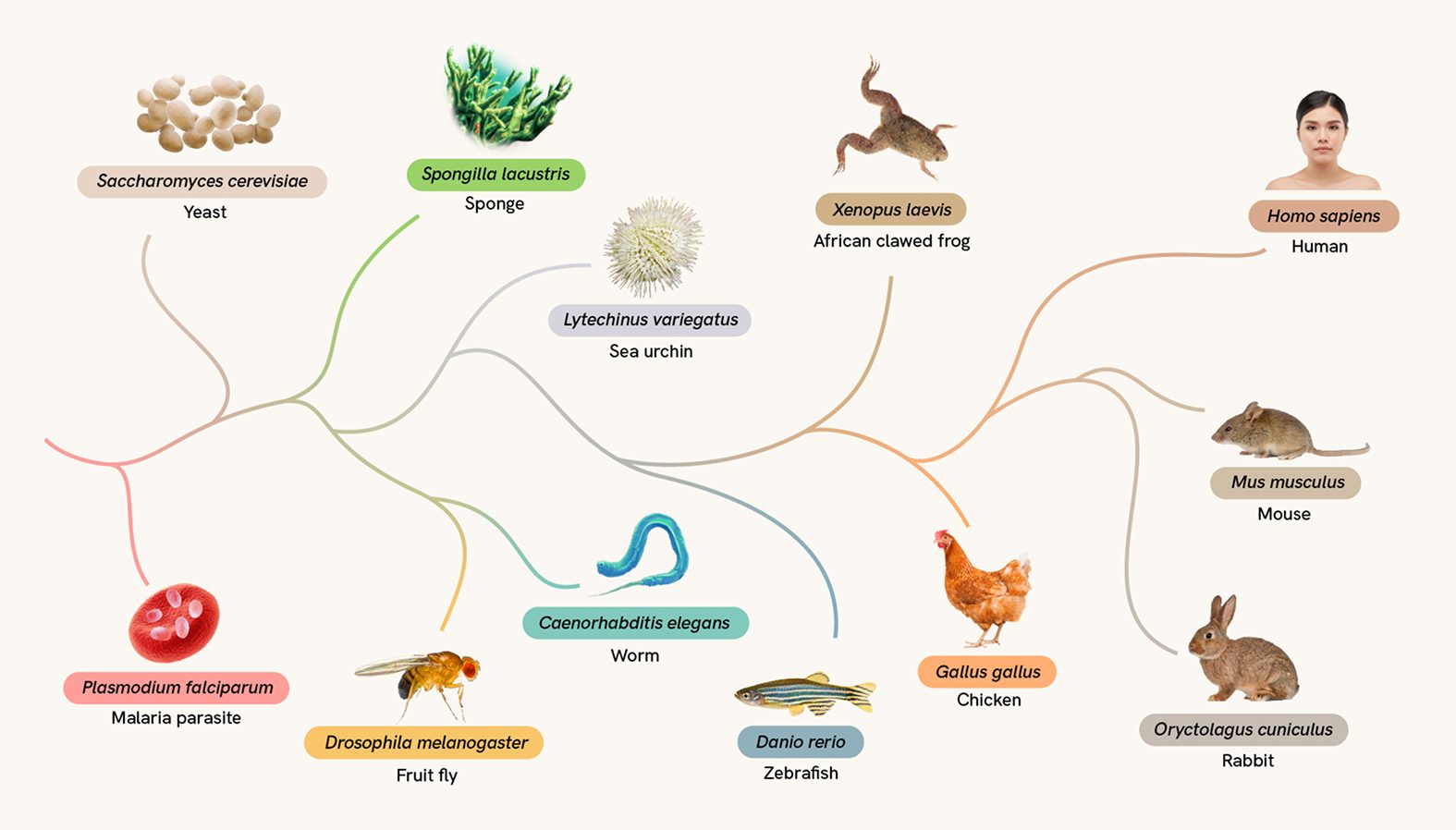
Understanding cells across billions of years of evolutionary history will help researchers uncover new insights into cells and their functions. TranscriptFormer is the first generative, multi-species model for single-cell transcriptomics. It was trained on 112 million cells from 12 different species, covering 1.5 billion years of evolution and representing the most evolutionarily diverse corpus of training data. The training data were sourced from CZ CELLxGENE, Tabula Sapiens and ZebraHub, as well as other publicly available datasets.
TranscriptFormer represents a significant advancement in biological models to help discover how cells work — across different tissues, in different states like infection or disease, and especially across species. It is an important step towards virtual cell models, where computational experimentation, rather than time-intensive lab experiments, can help speed up the discovery process and give more immediate feedback on research questions.
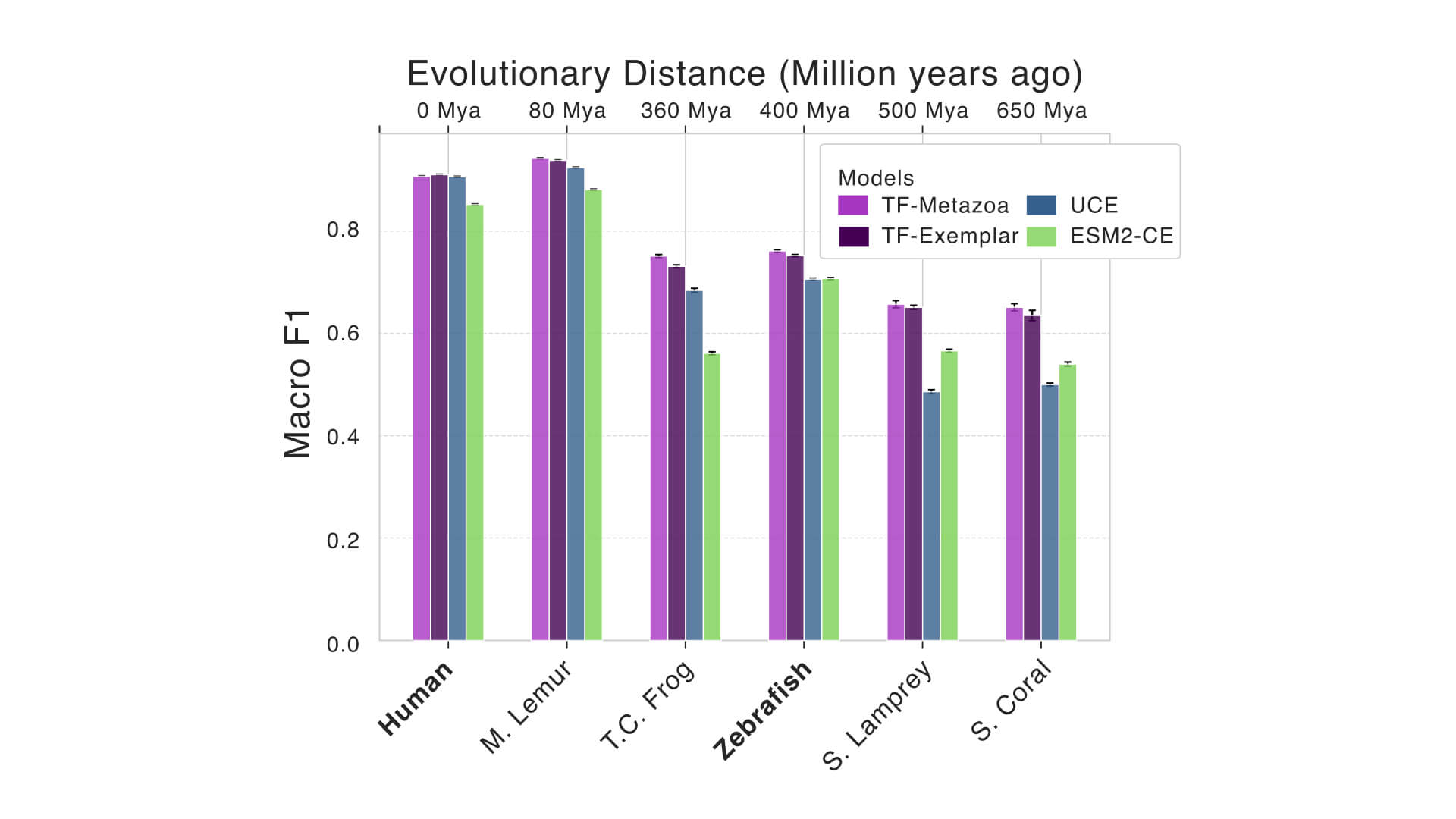
TranscriptFormer demonstrates state-of-the-art performance classifying cells and identifying disease states across species — even those it was not pretrained on — without including labeled data like cell types, donors or species. It is the first systematic comparison of training data sets across species and outpaces comparable models in tasks such as out-of-distribution species cell type classification.
Models like TranscriptFormer could help get us closer to understanding our underlying biology as viewed through the prism of evolution and conserved gene expression patterns, and we can use that information to better understand and treat, and even prevent, disease in the future.
Researchers can use TranscriptFormer to predict what different types of cells are, whether a cell is diseased, and how genes interact. It’s named for its transformer-based architecture and its generative pre-training on cell transcripts, the RNA-based copy of genetic instructions in a cell.
TranscriptFormer, which we detail in a new preprint, is an important step towards our goal of building an AI-based virtual cell model to predict and understand cell behavior.
What Researchers Can Do With TranscriptFormer
1. Predict Cell Types Across Evolutionary Distances, Including Out-of-Distribution Species
TranscriptFormer is able to identify cell types in species it hasn’t seen before — like rhesus macaque and marmoset — translating gene expression patterns/biological patterns across species. It can also transfer labels across related species as shown in a case study of spermatogenesis. This is useful for health research in predicting whether a finding in one type of species might translate to human cells. It will also enable annotation of cell types in species that have yet to be mapped and, in the future, completion of atlases where limited cells can be sampled. You can explore this capability using an easy-to-run tutorial on CZI’s virtual cell platform, which guides users step-by-step through using TranscriptFormer to generate embeddings and predict cross-species cell type annotations (see paper Fig. 2).
2. Predict Disease States
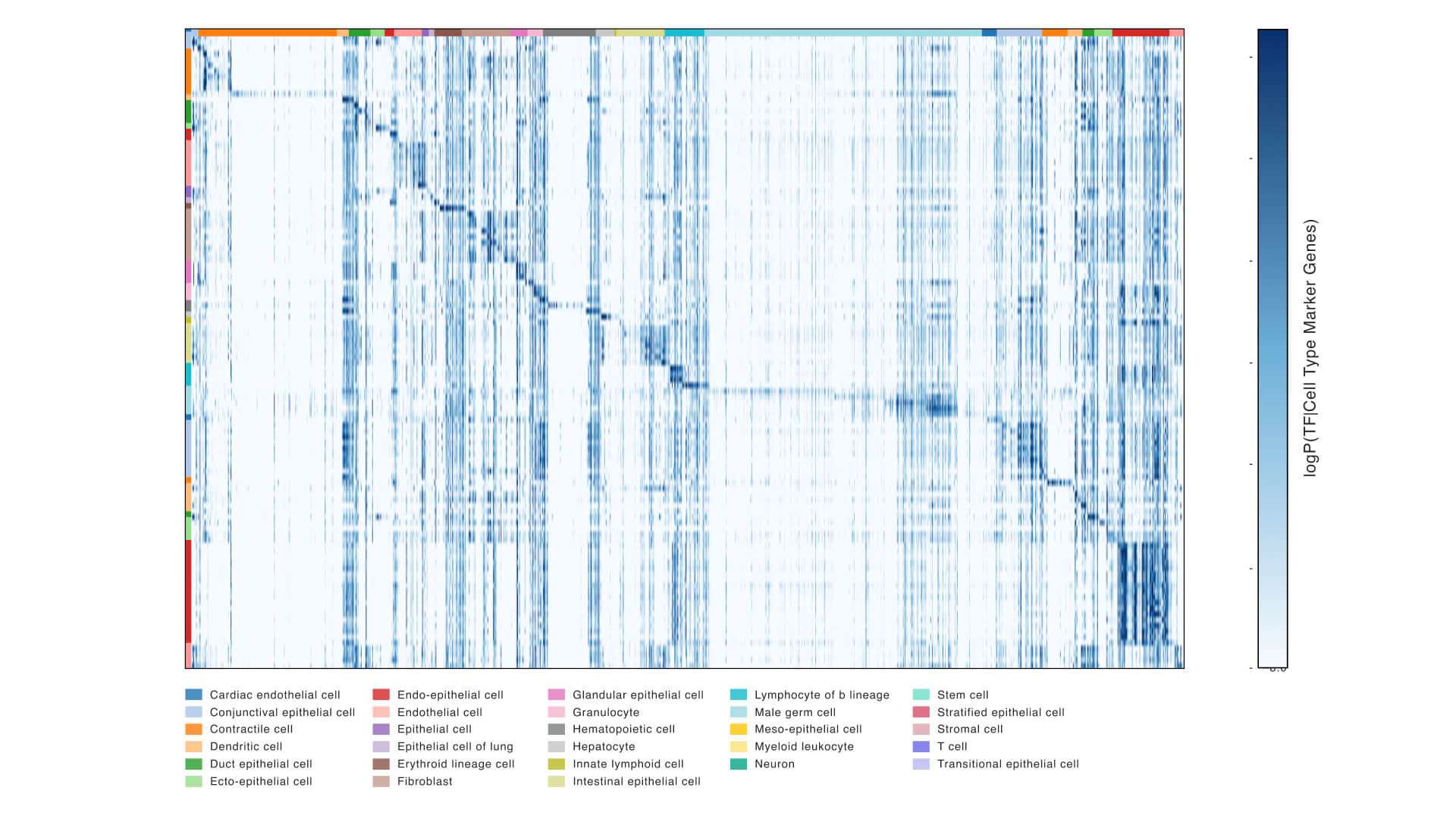
TranscriptFormer can be used to spot cell types or gene activity linked to infection or disease states without fine-tuning or training on a given disease. It surpassed baseline models at identifying SARS-CoV-2-infected cells from non-infected cells in the COVID Lung atlas, demonstrating its utility to predict which cells may or may not be infected in datasets where infection is unknown or can’t be rigorously identified. Further, it can be used to study host-pathogen interactions at single-cell resolution, identify cell-specific responses to viral infection, and uncover novel mechanisms of pathogenesis and cellular defense (see paper Fig. 3C/D).
3. Predict Gene-Gene Interactions via Prompting
We show how prompting TranscriptFormer as a generative model allows simulation of how genes work together in different cell types and conditions, including identifying which genes are co-expressed in specific cell types in a given tissue and organism. This can be used to probe the model for knowledge directly contained within the cell atlases it has ingested, or make predictions even outside it. TranscriptFormer can also produce contextualized gene embeddings that capture cell-specific gene representations, providing more granular biological context and mechanistic understanding of broader transcriptomic trends (see paper Fig. 4 & 5).
What’s Next
TranscriptFormer is the first step in a series of models aimed at better predicting and understanding cell behavior. We will continue to iterate and improve this model, as well as develop new models that combine multiple modalities, like microscopy and transcriptomics.
We’re committed to making curated models, datasets, and other resources generated by CZI and the research community openly available to scientists for collaboration, iteration and discovery. We believe this effort to build virtual cells will have broad applications for biomedical research, disease diagnosis and therapeutic development — bringing scientists closer to curing, preventing and managing all diseases by the end of this century. Read more from our researchers on building the TranscriptFormer model.
Access TranscriptFormer


Sorry, marketing cookies are required to view this form.